Local FNO on Darcy Flow¶
| Metadata | Value |
|---|---|
| Level | Intermediate |
| Runtime | ~5 min (CPU) / ~1 min (GPU) |
| Prerequisites | JAX, Flax NNX, FNO basics |
| Format | Python + Jupyter |
| Memory | ~2 GB RAM |
Overview¶
This tutorial demonstrates training a Local Fourier Neural Operator (LocalFNO) on the Darcy flow problem. LocalFNO combines global spectral convolutions with local spatial convolutions to capture both long-range dependencies and fine-grained local features.
The key insight is that many physical systems exhibit both global patterns (e.g., overall flow direction) and local features (e.g., boundary layers, sharp gradients). LocalFNO addresses this by processing inputs through both spectral (global) and convolutional (local) branches, then combining the results.
This example uses the standard operator-learning recipe — grid positional embedding, Gaussian input/output normalization, and the relative-L2 loss — to reach a low relative L2 error (~1-2%) on Darcy flow, and compares LocalFNO against a standard FNO baseline.
What You'll Learn¶
- Understand LocalFNO architecture: spectral + local convolution branches
- Apply the operator-learning recipe: grid embedding, normalization, relative-L2 loss
- Create a
LocalFourierNeuralOperatorwith configurable kernel size - Compare LocalFNO vs standard FNO on the same problem
- Analyze the trade-off between accuracy and parameter count
Coming from NeuralOperator (PyTorch)?¶
If you are familiar with the neuraloperator library:
| NeuralOperator (PyTorch) | Opifex (JAX) |
|---|---|
| No built-in LocalFNO | LocalFourierNeuralOperator(..., kernel_size=3) |
| Manual local convolution layers | Built-in spectral + local branch combination |
torch.compile |
@nnx.jit for XLA compilation |
torch.nn.Conv2d for local ops |
nnx.Conv with automatic NHWC/NCHW conversion |
Key differences:
- Integrated local branch: Opifex's LocalFNO has built-in local convolution per layer
- Mixing weight: Configurable
mixing_weightcontrols spectral vs local balance - Residual connections: Optional skip connections for improved gradient flow
- Factory functions:
create_turbulence_local_fno(),create_wave_local_fno()presets
Files¶
- Python Script:
examples/neural-operators/local_fno_darcy.py - Jupyter Notebook:
examples/neural-operators/local_fno_darcy.ipynb
Quick Start¶
Run the Python Script¶
Run the Jupyter Notebook¶
Core Concepts¶
LocalFNO Architecture¶
LocalFNO extends FNO by adding a local convolution branch in each layer:
graph LR
subgraph Input
A["Permeability Field<br/>a(x) : (1, 32, 32)"]
end
subgraph LocalFNO["Local Fourier Neural Operator"]
B["Lifting<br/>1 → 32 channels"]
C["LocalFourierLayer 1"]
D["LocalFourierLayer 2"]
E["LocalFourierLayer 3"]
F["LocalFourierLayer 4"]
G["Projection<br/>32 → 1 channels"]
end
subgraph Output
H["Pressure Field<br/>u(x) : (1, 32, 32)"]
end
A --> B --> C --> D --> E --> F --> G --> HLocalFourierLayer Detail¶
Each layer processes input through two parallel branches:
graph TB
A["Input x"] --> B["Spectral Branch<br/>(FFT → Spectral Conv → iFFT)"]
A --> C["Local Branch<br/>(Conv2D, kernel=3)"]
B --> D["α × spectral"]
C --> E["(1-α) × local"]
D --> F["Sum + Skip"]
E --> F
A --> F
F --> G["GELU Activation"]
G --> H["Output"]
style B fill:#e3f2fd,stroke:#1976d2
style C fill:#fff3e0,stroke:#f57c00Where α is the mixing_weight parameter (default 0.5).
When to Use LocalFNO¶
| Problem Type | Standard FNO | LocalFNO |
|---|---|---|
| Smooth solutions | Good | Comparable |
| Sharp gradients | Limited | Better |
| Boundary layers | Limited | Better |
| Turbulence (multi-scale) | Good | Better |
| Memory-constrained | Better | More params |
Implementation¶
Step 1: Imports and Setup¶
import jax
import jax.numpy as jnp
import numpy as np
from flax import nnx
from opifex.core.training import Trainer, TrainingConfig
from opifex.core.training.config import LossConfig
from opifex.data.loaders import create_darcy_loader
from opifex.neural.operators.common.embeddings import GridEmbedding2D
from opifex.neural.operators.fno.base import FourierNeuralOperator
from opifex.neural.operators.fno.local import LocalFourierNeuralOperator
Terminal Output:
======================================================================
Opifex Example: Local FNO on Darcy Flow
======================================================================
JAX backend: gpu
JAX devices: [CudaDevice(id=0)]
Resolution: 32x32
Training samples: 1000, Test samples: 100
FNO config: modes=(12, 12), width=32, layers=4
Local kernel size: 3
Step 2: Data Loading and Normalization¶
create_darcy_loader returns a frozen PDELoaders bundle whose .train and
.val attributes are datarax pipelines that yield channels-first batches
({"input": (b, 1, H, W), "output": (b, 1, H, W)}). The train/val split is
controlled by val_fraction. We collect each pipeline into arrays, fit Gaussian
statistics on the training set, then normalize all splits. Predictions are
un-normalized before computing the physical-space relative-L2 error.
n_samples = N_TRAIN + N_TEST
loaders = create_darcy_loader(
n_samples=n_samples,
batch_size=BATCH_SIZE,
resolution=RESOLUTION,
val_fraction=N_TEST / n_samples,
seed=SEED,
)
def _collect(pipeline) -> tuple[np.ndarray, np.ndarray]:
inputs, outputs = [], []
for batch in pipeline:
inputs.append(np.asarray(batch["input"]))
outputs.append(np.asarray(batch["output"]))
return np.concatenate(inputs, axis=0), np.concatenate(outputs, axis=0)
X_train, Y_train = _collect(loaders.train)
X_test, Y_test = _collect(loaders.val)
x_mean, x_std = X_train.mean(), X_train.std()
y_mean, y_std = Y_train.mean(), Y_train.std()
X_train_n = (X_train - x_mean) / x_std
Y_train_n = (Y_train - y_mean) / y_std
Terminal Output:
Generating Darcy flow data and serving via datarax...
Training data: X=(1024, 1, 32, 32), Y=(1024, 1, 32, 32)
Test data: X=(128, 1, 32, 32), Y=(128, 1, 32, 32)
Input mean/std: 0.1778 / 0.1302
Output mean/std: 0.213690 / 0.155666
Step 3: Model Creation¶
LocalFNO operates on channels-first tensors and does not append grid coordinates
internally, so we wrap it with GridEmbedding2D. The embedding appends normalized
(x, y) coordinate channels — the standard positional encoding that lets spectral
operators resolve the Dirichlet boundary of the Darcy problem.
class LocalFNOWithGrid(nnx.Module):
def __init__(self, in_channels, out_channels, hidden_channels,
modes, num_layers, kernel_size, *, rngs):
super().__init__()
self.grid_embedding = GridEmbedding2D(
in_channels=in_channels,
grid_boundaries=[[0.0, 1.0], [0.0, 1.0]],
)
self.local_fno = LocalFourierNeuralOperator(
in_channels=self.grid_embedding.out_channels,
out_channels=out_channels,
hidden_channels=hidden_channels,
modes=modes,
num_layers=num_layers,
kernel_size=kernel_size,
use_residual_connections=True,
rngs=rngs,
)
def __call__(self, x):
x_hwc = jnp.moveaxis(x, 1, -1)
x_embedded = self.grid_embedding(x_hwc)
x_chw = jnp.moveaxis(x_embedded, -1, 1)
result = self.local_fno(x_chw)
return result[0] if isinstance(result, tuple) else result
Terminal Output:
Creating LocalFNO model with grid embedding...
LocalFNO parameters: 365,099
Creating standard FNO for comparison...
Standard FNO parameters: 2,368,001
LocalFNO overhead: -84.6%
Step 4: Training¶
We train both operators with Opifex's Trainer and the relative-L2 loss — the
standard operator-learning objective — over 120 epochs.
config = TrainingConfig(
num_epochs=120,
learning_rate=1e-3,
batch_size=32,
validation_frequency=10,
verbose=True,
loss_config=LossConfig(loss_type="relative_l2"),
)
trainer = Trainer(model=model, config=config, rngs=nnx.Rngs(42))
trained_model, metrics = trainer.fit(
train_data=(jnp.array(X_train_n), jnp.array(Y_train_n)),
val_data=(jnp.array(X_test_n), jnp.array(Y_test_n)),
)
Terminal Output:
Training LocalFNO (Adam lr=0.001, relative-L2 loss)...
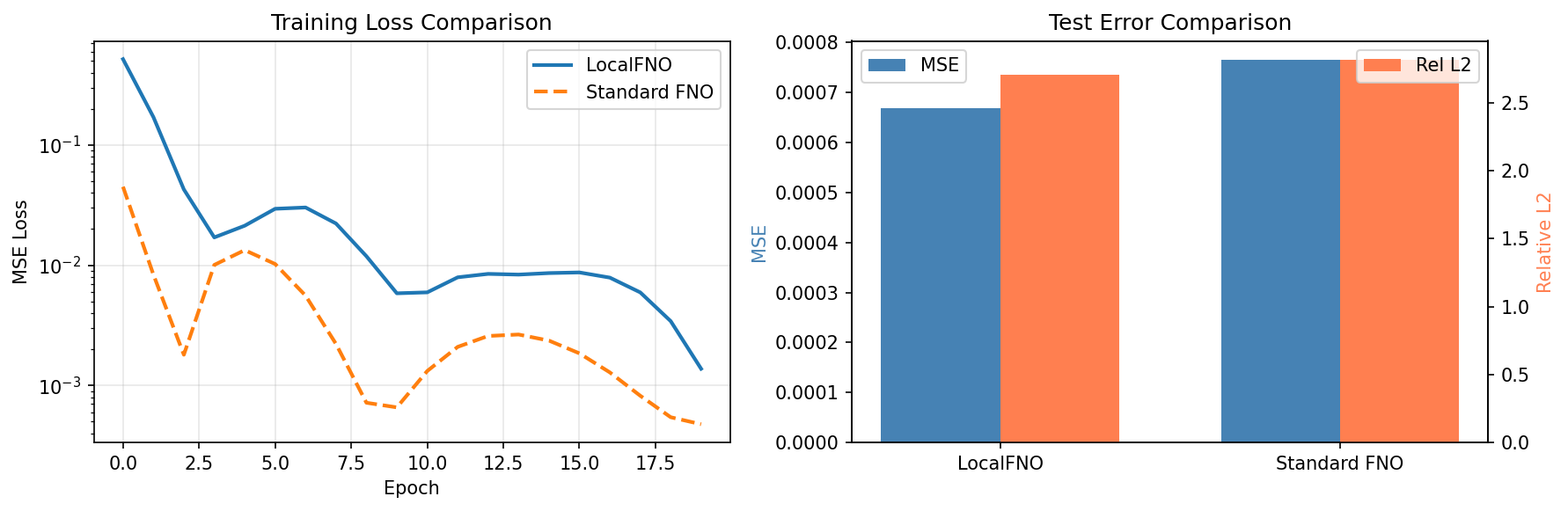
LocalFNO training completed in 28.3s
Final train loss: 0.03138274699449539
Final val loss: 0.0015184583608061075
Training Standard FNO (Adam lr=0.001, relative-L2 loss)...
Standard FNO training completed in 12.0s
Final train loss: 0.014661458320915699
Final val loss: 0.0005813310854136944
Step 5: Evaluation¶
Predictions are un-normalized back to physical pressure before measuring the relative L2 error, and the test set is run through each model in batches.
Terminal Output:
Running evaluation...
LocalFNO Results:
Test MSE: 3.050878e-05
Relative L2: 0.021260 (min=0.011985, max=0.043115)
Standard FNO Results:
Test MSE: 1.134721e-05
Relative L2: 0.012744 (min=0.007010, max=0.035330)
Comparison:
MSE improvement (LocalFNO vs FNO): -168.9%
Rel L2 improvement: -66.8%
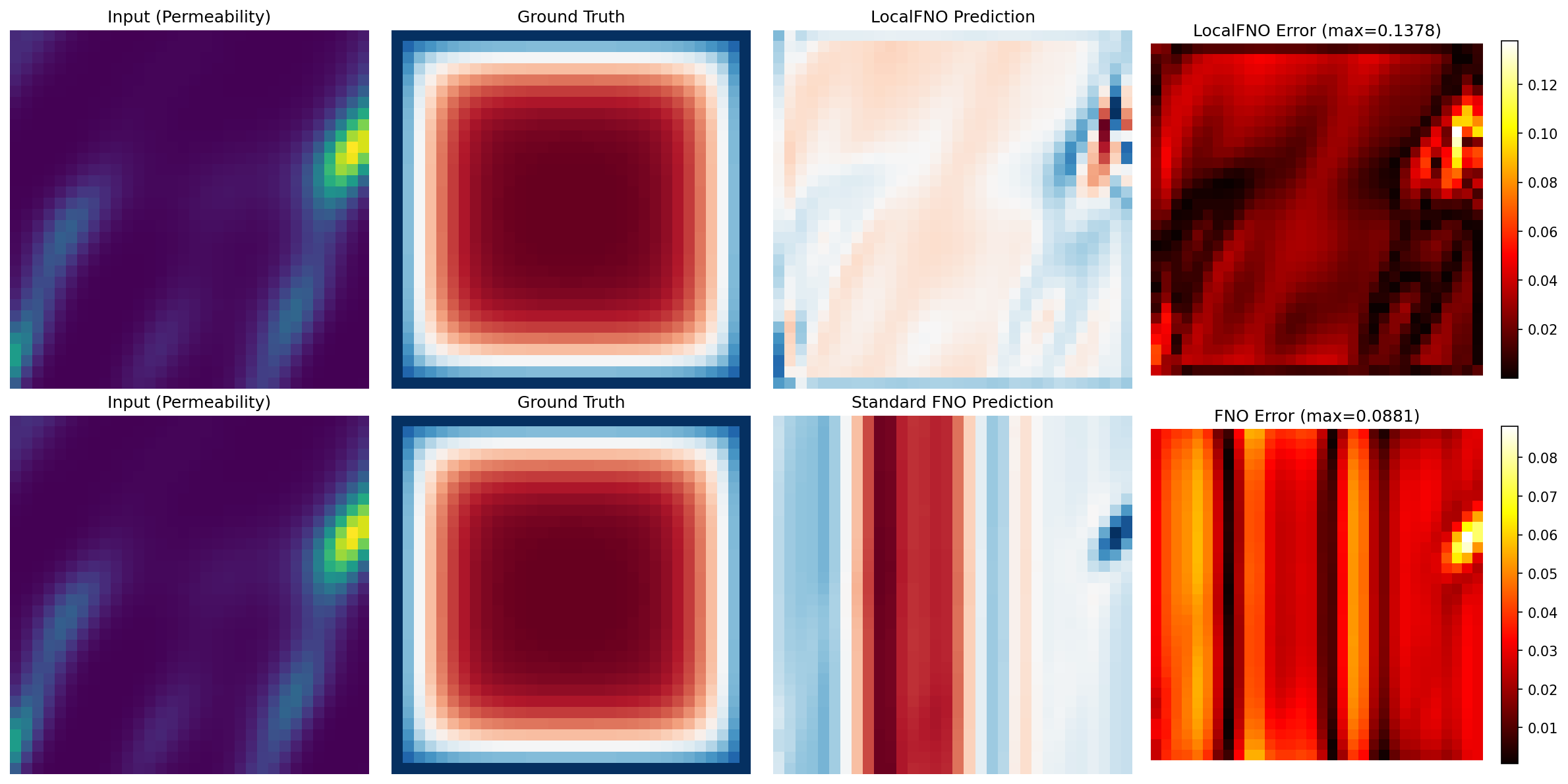
Visualization¶
Predictions Comparison¶
Training and Error Analysis¶
Results Summary¶
| Metric | LocalFNO | Standard FNO |
|---|---|---|
| Test MSE | 3.05e-05 | 1.13e-05 |
| Relative L2 Error | 0.0213 | 0.0127 |
| Parameters | 365,099 | 2,368,001 |
Both operators reach low single-digit-percent relative L2 on the corrected Darcy data. The standard FNO is slightly more accurate here, while LocalFNO reaches comparable accuracy with roughly 6x fewer parameters thanks to its local convolution branch. On smooth solutions like Darcy flow the spectral branch dominates; LocalFNO's local branch pays off most on problems with sharp gradients or boundary layers.
Next Steps¶
Experiments to Try¶
- Vary kernel size: Try
kernel_size=5orkernel_size=7for larger receptive fields - Adjust mixing weight: Use
mixing_weight=0.3to emphasize local features - Disable residual connections: Set
use_residual_connections=Falsefor comparison - Apply to turbulence: Use
create_turbulence_local_fno()preset for turbulent flows
Related Examples¶
| Example | Level | What You'll Learn |
|---|---|---|
| FNO on Darcy Flow | Intermediate | Standard FNO baseline |
| FNO on Burgers Equation | Intermediate | 1D temporal evolution |
| U-FNO on Turbulence | Advanced | Multi-scale U-Net + FNO |
API Reference¶
LocalFourierNeuralOperator- Local FNO model classLocalFourierLayer- Individual local Fourier layercreate_turbulence_local_fno- Preset for turbulent flowscreate_darcy_loader- Darcy flow data loader
Troubleshooting¶
Relative L2 error is high (> 0.5)¶
Symptom: Relative L2 stays near 0.5-0.7 even after training.
Cause: Missing the operator-learning recipe — no grid positional embedding, no input/output normalization, or the MSE loss instead of relative-L2.
Solution: Apply the full recipe used in this example: wrap the model in
GridEmbedding2D, fit Gaussian statistics on the training set and normalize all
splits, use LossConfig(loss_type="relative_l2"), and train with ~1000 samples for
enough epochs. Remember to un-normalize predictions before measuring the physical
relative-L2 error.
Training is slower than standard FNO per epoch¶
Symptom: Each LocalFNO epoch takes longer than the standard FNO.
Cause: The extra local convolution branch adds computation per layer.
Solution: LocalFNO is designed for problems where local features matter. For smooth problems like Darcy flow, a standard FNO is competitive. For multi-scale problems with sharp gradients, LocalFNO's accuracy-per-parameter advantage justifies the extra cost.
Out-of-memory during evaluation¶
Symptom: RESOURCE_EXHAUSTED error when running the full test set at once.
Solution: Run the forward pass in batches (this example uses a batch size of 128):